Im dritten Kapitel basteln wir ein universelles Eingabegerät für Informationen. Dafür verwenden wir einen Infrarot-Abstandssensor, mit dem wir Bits kodieren können. Diese Bits könnten dann etwa Texte repräsentieren. Oder ganz andere Dinge.
Der Weg dahin führt über folgende Schritte:
#
Was?
Wo?
1
Wir machen uns mit dem Infrarot-Abstandssensor vertraut.
Für dieses Kapitel benötigen wir erneut die LED (RGB LED Bricklet 2.0), ersetzen aber den Drehknopf aus Kapitel 2 durch einen Infrarot-Abstandssensor (Distance IR 4-30cm Bricklet 2.0). Beide Geräte schließen wir an den Mikrocontroller (Master Brick 3.2) an und fixieren sie auf einer Montageplatte. Wie in der Abbildung gezeigt, befestigen wir den Abstandssensor mit einem Metallwinkel so, dass er bündig mit der Platte ist und nach vorn zeigt.
Die vollständige Hardwareliste für dieses Kapitel sieht so aus:
Nutzt die Abbildung 3.1, um euren Aufbau zu kontrollieren.
(a) Seitenansicht.
(b) Draufsicht.
(c) Nahaufnahme des IR-Abstandssensors.
(d) Seitenansicht, leicht schräg.
Abbildung 3.1: Einfaches Setup mit einem Mikrocontroller, LED und einem Infrarot-Abstandssensor.
3.1.2 Erste Schritte mit dem Abstandssensor
Wie bei der LED werfen wir zuerst einen Blick auf den neuen Abstandssensor im Brick Viewer. Schließt dazu euren Master Brick per USB an, startet den Brick Viewer und klickt auf Connect. Im Tab Setup sollten nun neben der LED auch der Abstandssensor erscheinen. Denkt daran: Dort findet ihr auch die UID eurer Geräte – die braucht ihr gleich im Programm.
Abbildung 3.2: Nach erfolgreicher Verbindung erscheint der Infrarot-Entfernungsmesser in der Übersicht des Brick Viewers.
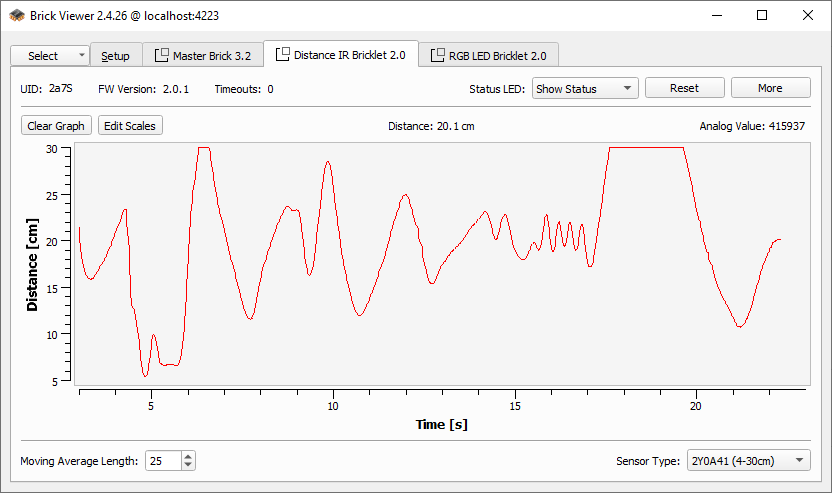
Wechselt in den Tab für den Abstandssensor, wo ihr ihn direkt testen könnt: Ihr seht die aktuelle Entfernung, die der Sensor misst, in Echtzeit oben in der Mitte (in Zentimetern). Darunter zeigt ein Kurvendiagramm den zeitlichen Verlauf. Bewegt eure Hand vor dem Sensor, um ein Gefühl für sein Verhalten zu bekommen. Was passiert, wenn ihr sehr nah vor dem Sensor seid? Und was, wenn ihr eure Hand weiter weg bewegt?
Abbildung 3.3: Der Brick Viewer zeigt die aktuelle Entfernung im Zeitverlauf an.
3.2 Lichtschranke
Einen Infrarot-Abstandssensor verwenden wir in der Praxis zur berührungslosen Messung des Abstands zu einem Objekt. Der Sensor sendet einen unsichtbaren Infrarotlichtstrahl aus und misst das Licht, das vom Objekt zurückgeworfen wird. Anhand der Intensität oder des Winkels des zurückkehrenden Lichts berechnet der Sensor die Entfernung. Diese Sensoren sind aus der Praxis nicht wegzudenken und kommen in vielen Szenarien zum Einsatz, zum Beispiel:
Objekterkennung an einem Fließband
Füllstandsmessung in Behältern
Hinderniserkennung für Roboter, etwa bei Staubsaugerrobotern
Positionierung von Werkstücken in Maschinen
Einparkhilfe beim Auto
Letztlich lassen sich alle Anwendungsfälle auf zwei Fragen reduzieren:
Befindet sich ein Objekt in der Sicht des Sensors?
Wie weit ist ein Objekt vom Abstandssensor entfernt?
Wir starten mit der einfacheren der beiden Fragen: Befindet sich ein Objekt in der Sicht des Sensors? Das beschreibt im Kern die Funktion einer Lichtschranke.
Wie ihr beim Ausprobieren im Brick Viewer festgestellt habt, misst der Sensor Entfernungen zwischen 4 und 30 cm. Das bedeutet: Objekte außerhalb dieses Bereichs werden nicht erkannt – weder näher als 4 cm noch weiter als 30 cm. Eine Lichtschranke hat somit die Aufgabe zu prüfen, ob der IR-Abstandssensor einen Wert kleiner als 30 cm misst. Dann befindet sich ein Objekt in seiner Sichtlinie.
Verbinden wir uns mit dem Sensor und schreiben das notwendige Grundgerüst. Tragt eure UIDs ein und legt beide Bricklets an, Sensor und LED:
Listing 3.1: Boilerplate-Code für IR-Abstandssensor und RGB-LED
Der Sensor ist danach in der Variablen ir gespeichert. Über sie können wir seine Funktionen aufrufen. Eine davon erlaubt uns das Auslesen des aktuell gemessenen Werts:
distance = ir.get_distance()
Ein Blick in die Dokumentation verrät, dass der Rückgabewert in Millimetern angegeben wird. Ein Wert an der oberen Grenze (rund 300 mm) signalisiert typischerweise, dass sich kein Objekt innerhalb der Reichweite befindet. Damit wir besser testen können, lesen wir den Wert kontinuierlich aus und schreiben ihn auf die Konsole:
Ihr werdet sehen, dass wir sehr viele Ausgaben erzeugen, weil in jedem Schleifendurchlauf der Wert ausgegeben wird – auch wenn er sich nicht verändert hat. Geben wir erneut nur die Veränderungen aus, um die Ausgaben zu reduzieren:
Ihr erinnert euch: Dasselbe Prinzip haben wir in Abschnitt 2.7 verwendet, um nur bei einer Änderung des Drehknopfs eine Ausgabe zu erzeugen. Wir merken uns den letzten Wert und vergleichen ihn mit dem aktuell gemessenen. Ist er gleich, passiert nichts. Hat er sich verändert (distance != last_distance), geben wir den neuen Wert aus und aktualisieren den letzten Wert (last_distance = distance).
Wir sind unserem Etappenziel einer Lichtschranke schon sehr nah. Anhand der Ausgabe könnten wir entscheiden, ob ein Objekt in der Sicht des Sensors ist oder nicht. Das soll aber unser Programm automatisch erledigen. Dazu fügen wir eine weitere Bedingung mit einer if-Anweisung hinzu:
last_distance =0whileTrue: distance = ir.get_distance()if last_distance != distance:if distance <300:print(f"Objekt erkannt: {distance} mm")else:print("Kein Objekt in Reichweite") last_distance = distance
Die neue if-Anweisung prüft, ob der Abstand kleiner als 300 mm ist. Dann befindet sich etwas vor dem Sensor. In diesem Fall geben wir einen entsprechenden Hinweis aus. Andernfalls kommt der Hinweis „Kein Objekt in Reichweite“. Diesen anderen Fall bildet der optionale else-Teil ab. Code hinter else wird immer dann ausgeführt, wenn keine der vorher definierten Bedingungen über if oder elif zutrifft.
Damit unsere Lichtschranke auch ohne Blick auf die Konsole funktioniert, bringen wir im letzten Schritt die LED ins Spiel. Sie soll rot aufleuchten, wenn ein Objekt erkannt wird. Die LED haben wir bereits kennengelernt, den Code können wir übernehmen:
Die LED leuchtet rot, wenn ein Objekt erkannt wird.
2
Die LED schaltet sich aus, wenn kein Objekt mehr erkannt wird.
Probiert es aus – die Lichtschranke sollte funktionieren und Objekte innerhalb von 30 cm zuverlässig erkennen.
3.3 Hinderniserkennung
Die Lichtschranke leuchtet immer rot, sobald ein Objekt erkannt wird. Dabei spielt die Entfernung keine Rolle. Lasst uns die Idee zu einer Hinderniserkennung für einen hypothetischen Staubsaugerroboter erweitern. Die LED soll anzeigen, ob sich ein Objekt bereits nahe am Roboter befindet oder ob es noch weit genug entfernt ist.
Nehmen wir an, dass Objekte, die 17 cm oder näher am Roboter sind, als Gefahr gelten. Alles, was zwischen 17 und 30 cm Abstand hält, sieht der Roboter nicht als bedrohlich an. Die drei Zustände wollen wir über die Farbe der LED abbilden:
Gelb: Objekt in mittlerer Entfernung erkannt (17 cm < Abstand < 30 cm)
Rot: Nahes Objekt erkannt (<= 17 cm)
Aus: Kein Objekt vor dem Sensor (>= 30 cm)
Wir können dazu den Code der Lichtschranke erweitern:
Listing 3.2: Der Code für die zweistufige Hinderniserkennung.
Die LED leuchtet gelb, wenn ein Objekt in mittlerer Entfernung erkannt wird.
2
Die LED leuchtet rot, wenn ein Objekt in naher Entfernung erkannt wird.
3
Die LED schaltet sich aus, wenn kein Objekt mehr erkannt wird.
Ihr erinnert euch an die additive Farbmischung aus Abbildung 1.6 (a)? Gelb entsteht durch die Kombination von Rot und Grün. Wir verwenden hier eine elif-Anweisung, die eine weitere Bedingung prüft, wenn die vorherige if-Bedingung nicht zutrifft. So können wir mehrere Bedingungen hintereinander prüfen. Der letzte else-Teil fängt alle Fälle ab, in denen kein Objekt erkannt wurde.
Unser Staubsaugerroboter könnte den Code oben verwenden, um Hindernisse zu erkennen und bei zu großer Nähe ein Ausweichmanöver zu starten.
3.4 Universelles Eingabegerät
Eine andere Möglichkeit, den Abstandssensor und den Code aus Listing 3.2 zu verwenden, ist ein Eingabegerät für Informationen in unseren Computer. Wie soll ein Abstandssensor als Eingabegerät für Informationen fungieren?
Wie wir später noch sehen werden, benötigen wir für die Darstellung von Informationen unterschiedliche Zustände – mindestens zwei. Genau das verkörpert das Bit, das wir in Abschnitt 2.6 kennengelernt haben: Ein Bit hat zwei Zustände, an oder aus, 0 oder 1.
Was wäre, wenn wir die beiden Bereiche „nah“ und „weit genug entfernt“ nicht länger als Entfernungen interpretieren, sondern einfach als zwei Zustände? Sagen wir, der Bereich „weit genug entfernt“ steht für die 1 und der Bereich „nah“ für die 0. Dann könnten wir über die bewusste Platzierung eines soliden Gegenstands und anschließende Messung der Entfernung den Zustand eines Bits kodieren:
Wenn ihr den Code ausführt, werdet ihr ein Problem erkennen: Platzieren wir unsere Hand nahe am Sensor, um eine 0 zu kodieren, gibt das Programm nacheinander sehr viele Nullen aus. Dasselbe gilt für Einsen. Dabei wollen wir mit einer Handgeste jeweils nur eine 1 oder 0 übermitteln, nicht eine ganze Reihe. Das liegt daran, dass sich unsere Hand ständig minimal bewegt – ein Millimeter reicht.
Wir müssen unser Programm so anpassen, dass es nicht erneut auf eine Änderung reagiert, solange die Hand nicht wieder weggenommen wurde. Das erkennen wir daran, dass der Sensor die maximale Entfernung von 30 cm misst. Erst wenn dieses Ereignis wieder auftritt, soll ein neuer Zustand kodiert werden.
Eine Lösung besteht darin, dass wir uns merken, ob unser Eingabegerät aktuell empfangsbereit ist oder nicht. Wir führen dafür die Variable receiving ein, die den Zustand unseres Eingabegeräts beschreibt. Ist sie True, ist das Gerät bereit, eine Eingabe zu empfangen. Ist sie False, ignorieren wir alle Änderungen, bis die Hand wieder weggenommen wurde.
last_distance =0receiving =FalsewhileTrue: distance = ir.get_distance()if last_distance != distance:if receiving:if distance >170and distance <300:print(f"1 bei {distance} mm") receiving =Falseelif distance <=170:print(f"0 bei {distance} mm") receiving =Falseelse:if distance >=300: receiving =Trueprint("Bereit für den nächsten Code") last_distance = distance
1
Nur im Empfangsmodus wird anhand der Entfernung ein Bit kodiert.
2
Wenn wir nicht im Empfangsmodus sind, prüfen wir, ob die Hand wieder weggenommen wurde (>= 30 cm).
3
Wenn die Hand weg ist, schalten wir wieder in den Empfangsmodus.
Das sieht schon gut aus. Probiert aber einmal aus, eure Hand sehr langsam von oben nach unten vor den Sensor zu bewegen, und zwar im nahen Bereich, sodass eigentlich eine 0 kodiert werden sollte. In manchen Fällen erkennt das Programm fälschlicherweise eine 1 statt der 0. Warum ist das so? Der Sensor hat bei der Messung eine leichte zeitliche Verzögerung. Wenn er aktuell 30 cm Abstand misst und wir unsere Hand langsam nach unten bewegen, misst der Sensor zunächst einen Abstand knapp unter 30 cm. Das Programm reagiert sofort und kodiert eine 1, obwohl wenig später der Sensorwert in den Bereich der 0 kommt (zum Beispiel 8 cm).
Wir können das Problem umgehen, indem wir einen kleinen Verzug einbauen, sobald ein Unterschied erkannt wurde. Nach diesem zeitlichen Verzug messen wir erneut, um sicherzugehen, die korrekte Position der Hand zu erwischen. So könnte das im Code aussehen:
last_distance =0receiving =FalsewhileTrue: distance = ir.get_distance()if last_distance != distance:# 100 ms warten und erneut messen time.sleep(0.1) distance = ir.get_distance()if receiving:if distance >170and distance <300:print(f"1 bei {distance} mm") receiving =Falseelif distance <=170:print(f"0 bei {distance} mm") receiving =Falseelse:if distance >=300: receiving =Trueprint("Bereit für den nächsten Code") last_distance = distance
Testet es jetzt: Unser Eingabegerät erkennt die Zustände 0 und 1 zuverlässig.
3.5 Texte kodieren
Können wir unser universelles Eingabegerät dazu verwenden, dem Computer Texte zu diktieren? Schließlich bedeutet „universell“, dass es für viele Zwecke einsetzbar ist. Und die Antwort lautet: ja! Wenn wir ein Gerät entwickeln, mit dem wir Bits kodieren können, können wir damit alles eingeben, was ein Computer darstellen kann.
In Kapitel 2 haben wir gesehen, wie wir mit 8 Bits den Wert einer der drei Grundfarben im RGB-Code darstellen können. Wenn wir unser Eingabegerät einsetzen, um hintereinander 24 Bits zu übermitteln und diese als einen RGB-Farbcode zu interpretieren, könnten wir damit unsere LED in einer beliebigen Farbe aufleuchten lassen. Das versuchen wir später. Jetzt kümmern wir uns um eine ebenso wichtige Form der Information: Texte.
Texte bestehen allgemein aus Zeichen. Die meisten Zeichen in Texten sind Buchstaben, die wir in Klein- und Großbuchstaben unterscheiden. Dazu kommen Zahlen und Satzzeichen. Schaut auf das Keyboard eures Computers – dort findet ihr die meisten Zeichen, die ihr für Texte benötigt.
3.5.1 Wie viele Bits benötigen wir?
Genau wie bei den Farben, für die wir 24 Bits benötigen (jeweils 8 pro Farbe im RGB-Code), stellt sich bei Texten die Frage, wie viele Bits wir benötigen, um ein Zeichen darzustellen. Die Antwort hängt von der Anzahl der benötigten Zeichen ab.
Nähern wir uns von der anderen Seite und erweitern unseren Zeichencode Bit für Bit. Wir beginnen klein und fangen mit einem Bit an. Wenn wir Bits als Text interpretieren, wie viele Zeichen (oder Buchstaben) können wir dann mit einem einzigen Bit darstellen? Richtig: zwei!
Lasst das Programm laufen und legt eure Hand einmal nahe vor den Sensor, dann zweimal weiter weg und wieder nah. Das habt ihr gerade geschrieben: „ABBA“.
Neben der bekannten schwedischen Band lassen sich mit den Buchstaben A und B jedoch nicht viele andere Wörter bilden. Wir sind also gut beraten, mindestens ein zweites Bit hinzuzunehmen. Die Anzahl Bits, die wir für einen Buchstaben benötigen, erhöht sich damit auf zwei. Wie bilden wir das im Programm ab?
Am einfachsten, indem wir uns die Bits zunächst merken, sie also hintereinander in eine Zeichenkette schreiben. Sobald eine vorher definierte Länge einer Nachricht – hier zunächst zwei Bits – erreicht ist, dekodieren wir die Bitfolge und erhalten den passenden Buchstaben. Danach geht es wieder von vorn los und unsere Bit-Zeichenkette ist wieder leer.
Die Länge einer Nachricht. So viele Bits müssen wir sammeln, bis wir die Nachricht entschlüsseln können.
2
Wir erstellen eine leere Zeichenkette bits, in der wir jedes empfangene Bit speichern.
3
text sammelt die dekodierten Buchstaben zu einem Text.
4
Wir merken uns das Bit, indem wir es an das Ende von bits hinzufügen – hier eine „1“.
5
Dasselbe für eine „0“.
6
Wenn wir genug Bits zusammen haben, dekodieren wir die Bitfolge.
7
decode_letter(bits) wandelt die Bitfolge in einen Buchstaben um. Die Funktion implementieren wir gleich.
8
Wir fügen den Buchstaben dem bisherigen Text an.
9
Danach setzen wir die Bit-Zeichenkette zurück.
Direkt nach dem Start wartet das Programm darauf, dass ihr eure Hand vor den Sensor haltet. Jede erkannte Änderung wird nach 100 Millisekunden noch einmal gemessen, um den Wert zu stabilisieren. Befinden wir uns im Empfangsmodus (receiving ist True), schreiben wir je nach Abstand eine „1“ (weit) oder „0“ (nah) ans Ende der Zeichenkette bits und schalten den Empfang vorübergehend aus. Sobald die Länge von bits der erwarteten MESSAGE_LENGTH entspricht, rufen wir decode_letter(bits) auf, erhalten den passenden Buchstaben, hängen ihn an text an und leeren bits. Erst wenn der Sensor wieder mindestens 30 cm misst, schalten wir den Empfang erneut frei, damit die nächste Eingabe beginnen kann.
Okay – probieren wir es aus. Unser Programm sammelt das erste Bit, dann das zweite und dann…
NameError: name 'decode_letter' is not defined
Was ist das? Eine Fehlermeldung (wie sprechen auch von Bugs), die uns sagt: Die Funktion decode_letter() ist nicht definiert. Wir müssen sie also noch implementieren. Wir haben die Funktion zwar schon namentlich genannt, aber es gibt nirgends eine Definition. Das holen wir jetzt nach.
Erinnert euch an Abschnitt 2.10: Wir müssen wissen, was die Funktion tun soll, was sie dafür benötigt und was sie zurückgibt. Einen Namen haben wir bereits: decode_letter.
Die Funktion soll unsere Zeichenkette voller Bits der Länge zwei, also so etwas wie “00”, “01”, “10” oder “11”, in einen Buchstaben umwandeln. Die Eingabe ist bits und die Ausgabe ein Buchstabe, den diese Bitfolge kodiert. Unsere Funktion könnte so aussehen:
Mit einem if-Statement, begleitet von drei elif-Zweigen, prüfen wir, welchem der möglichen Werte die Zeichenkette bits entspricht, und geben einen Buchstaben A, B, C oder D zurück. Da es mit zwei Bits insgesamt vier Möglichkeiten gibt, können wir auch nur vier Buchstaben damit abbilden. Wir erweitern das weiter unten, damit wir alle Buchstaben des Alphabets abdecken können.
Unser aktuelles Codesystem für vier Buchstaben.
Bitfolge
Dezimalzahl
Buchstabe
00
0
A
01
1
B
10
2
C
11
3
D
Die Tabelle fasst unser Codesystem zusammen. In der zweiten Spalte haben wir zur Bitfolge die entsprechende Dezimalzahl eingetragen. Erinnert euch: Das Binärsystem ist ein Stellenwertsystem wie jedes andere auch, nur eben zur Basis 2. Wie ihr die entsprechende Dezimalzahl zu einer Binärzahl errechnet, haben wir in Abschnitt 2.5.3 gelernt.
Fügen wir die Funktion in unser Programm ein. Wichtig ist: Eine Funktion muss vor ihrer Verwendung definiert sein.
Cool, neben „ABBA“ können wir jetzt auch „ADAC“ schreiben. Wir wollen aber natürlich noch mehr, und bevor wir weiter Bit für Bit hinzufügen, überlegen wir, wie viele Bits wir eigentlich benötigen.
Es gibt 26 Buchstaben im Alphabet, und vielleicht wollen wir auch ein Leerzeichen kodieren. Die Unterscheidung zwischen Klein- und Großbuchstaben lassen wir an dieser Stelle einmal weg – sie wäre aber für ein praxistaugliches Codesystem wichtig. Somit sind es 27 Zeichen, die wir kodieren wollen. Mit jedem zusätzlichen Bit verdoppeln wir unsere Möglichkeiten, das haben wir in Abschnitt 2.6 gelernt. Rufen wir uns noch einmal die Tabelle in den Sinn, um zu erkennen, wie viele Bits wir benötigen.
Anzahl Bits und mögliche Kodierungen.
Anzahl Bits
Mögliche Kodierungen
1
\(2^1 = 2\)
2
\(2^2 = 4\)
3
\(2^3 = 8\)
4
\(2^4 = 16\)
5
\(2^5 = 32\)
6
\(2^6 = 64\)
7
\(2^7 = 128\)
8
\(2^8 = 256\)
Demnach reichen uns fünf Bits aus, denn damit können wir insgesamt 32 Kodierungen vornehmen. Wir hätten somit noch fünf freie Plätze, die wir vielleicht für Satzzeichen wie Punkt oder Komma verwenden.
Um das in unserem Programm zu reflektieren, müssen wir die Funktion decode_letter anpassen und gleichzeitig die Länge einer Nachricht auf 5 Bits erhöhen. Damit wir es etwas einfacher haben und die Buchstaben den Dezimalzahlen von 0–25 zuordnen können, wandeln wir die Bitfolge zuerst in eine Dezimalzahl um:
Die Funktion int wandelt die Bitfolge in eine Dezimalzahl um. Der erste Parameter ist die Bitfolge als String, der zweite die Basis (hier 2 für Binärzahlen).
Für die Umwandlung der Bitfolge verwenden wir die Funktion int(), die uns später noch öfter begegnen wird. Sie wandelt Zeichenketten in ganze Zahlen um, und wenn wir als zweiten Parameter die Basis des Zahlensystems angeben, funktioniert das auch mit Binärzahlen.
Die Lösung funktioniert, allerdings ist sie nicht besonders elegant. Wir müssen für jeden Buchstaben einen eigenen if/elif-Zweig schreiben, was schnell unübersichtlich wird. Zudem wird unser Code extrem lang – im Codeblock oben deutet ... bereits an, dass es noch viele weitere Buchstaben zwischen E und Z gibt. Glücklicherweise geht das eleganter, und zwar mit einem Wörterbuch.
3.5.2 Wörterbücher
Ein Dictionary (deutsch: Wörterbuch) ist in der Programmierung eine Sammlung von Schlüssel-Wert-Paaren. Über einen Schlüssel – zum Beispiel eine Zahl – greifen wir direkt auf den zugehörigen Wert zu, etwa einen Buchstaben. Stellt euch das wie ein Telefonbuch vor, bei dem ihr über den Namen die Nummer herausfindet. Das ist ideal, wenn wir Bitfolgen zuerst in Dezimalzahlen umwandeln und dann schnell den passenden Buchstaben nachschlagen möchten. Statt viele if/elif-Zweige zu schreiben, legen wir einmalig eine Nachschlagetabelle an. Das macht den Code kürzer, übersichtlicher und leichter erweiterbar.
Für unsere Zeichendekodierung können wir ein Dictionary nutzen, das die Dezimalwerte 0–25 auf „A“–„Z“ abbildet und zum Beispiel 26 als Leerzeichen reserviert. Damit wird decode_letter deutlich kompakter und leichter zu pflegen.
Mit geschweiften Klammern erzeugen wir ein leeres Dictionary.
2
Mit den eckigen Klammern können wir einem Schlüssel einen Wert zuweisen. Wenn es den Eintrag nicht gibt, wird er neu angelegt. Andernfalls wird er überschrieben.
Wenn ihr später weitere Zeichen (z. B. Punkt oder Komma) ergänzen wollt, könnt ihr sie einfach hinzufügen:
SYMBOLS[27] =","SYMBOLS[28] ="."
Wie ihr an der Schreibweise von SYMBOLS erkennen könnt, handelt es sich um eine Konstante. Logisch, schließlich verändert sich unser Codesystem für die Symbole im Verlauf des Programms nicht. Wir initialisieren ein leeres Dictionary mit geschweiften Klammern (Zeile 5). Die Zuweisung der Werte erfolgt dann über die eckigen Klammern, wobei in den eckigen Klammern der Schlüssel (englisch: Key) steht und der Wert, den wir dem Schlüssel zuweisen möchten, hinter dem Gleichheitszeichen folgt.
Prinzipiell könnten wir mit den eckigen Klammern auch Werte abfragen. Wenn wir zum Beispiel SYMBOLS[0] schreiben, erhalten wir den Wert “A” zurück. Wenn wir einen Schlüssel abfragen, der nicht existiert, bekommen wir jedoch einen Fehler. Eine bessere Möglichkeit zum Abfragen von Werten bietet daher die get()-Methode. Sie liefert den Wert für den Schlüssel zurück, den wir als erstes Argument übergeben. Wenn dieser Schlüssel nicht existiert, bekommen wir den Wert None zurück, was robuster ist, als wenn das Programm mit einem Fehler abbräche. Zudem können wir als zweites Argument einen Standardwert angeben, der zurückgegeben wird, wenn der Schlüssel nicht existiert. In unserem Fall ist das ein Fragezeichen “?”, das signalisiert, dass die Bitfolge keinem bekannten Buchstaben zugeordnet werden kann.
Überprüft euch selbst: Welcher Wert kommt bei folgendem Aufruf zurück?: SYMBOLS.get(5)
Listing 3.3: Der vollständige Code für die Texteingabe mit dem Infrarot-Abstandssensor.
Das Codebeispiel aus diesem Abschnitt findet ihr auf GitHub.
Klont das Repository und öffnet den Ordner in eurem Visual Studio Code, um es schnell ausführen zu können.
3.6 ASCII-Code
Im vorigen Abschnitt haben wir zusammen überlegt, wie wir Texte kodieren und als Bitfolge über ein universelles Eingabegerät basierend auf einem IR-Abstandssensor übertragen können. Ziemlich cool, findet ihr nicht? Dabei haben wir jedem Buchstaben eine eindeutige Bitfolge zugewiesen und sind letztlich auf unser eigenes 5-Bit-Kodierungssystem gekommen.
Weil eine der ersten Anwendungen mit dem Computer die Verarbeitung von Texten war, haben sich darüber, wie man Texte kodieren kann, schon andere sehr schlaue Leute Gedanken gemacht. Das Ergebnis ist der ASCII-Code, den es seit den 1960er-Jahren gibt und der weltweit standardisiert ist.
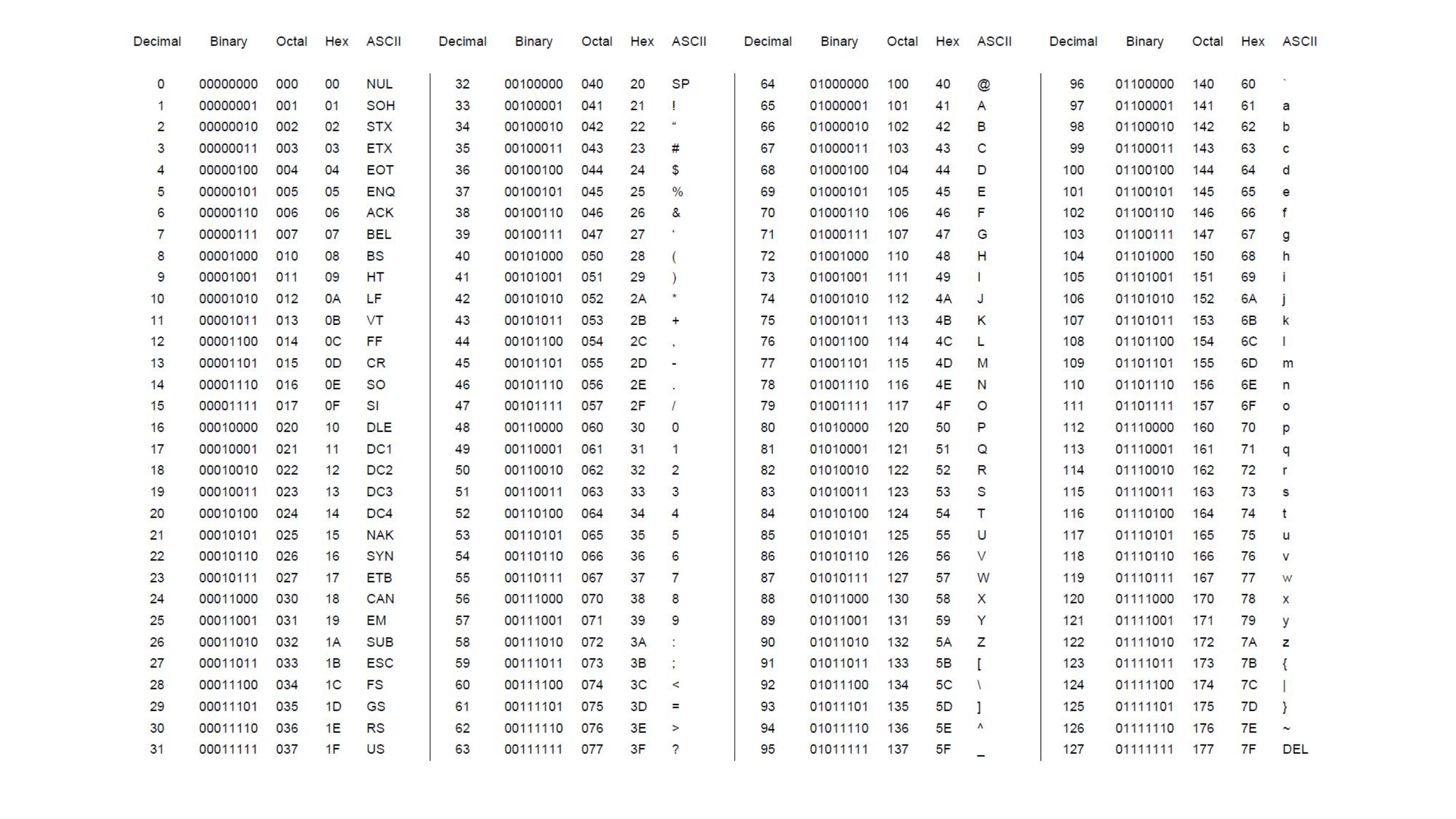
Der ASCII-Code basiert auf sieben Bits und kann somit 128 verschiedene Symbole verwalten. Die vollständige Liste an Symbolen seht ihr in Abbildung 3.4. Die Tabelle enthält fünf Spalten, wobei die ersten vier den Zahlencode für das kodierte ASCII-Zeichen in unterschiedlichen Zahlensystemen angeben. Ganz links seht ihr die Dezimalzahl, daneben die Binärdarstellung. Zusätzlich wird noch die Oktalzahl und die Hexadezimalschreibweise mit angezeigt. Oktal kennen wir bereits, was es mit Hexadezimal auf sich hat, lernen wir später in Kapitel 4.
Wenn ihr genau hinseht, erkennt ihr, dass die Binärzahl nicht aus 7, sondern aus 8 Bits besteht. Die erste Ziffer ganz links ist aber immer 0. Das liegt daran, dass Computer in 8-Bit-Einheiten, also in Bytes, denken. Auch der Speicher eines Computers ist so organisiert. Deshalb benötigt ein ASCII-Symbol in der Praxis statt sieben, acht Bits auf unserem Computer.
Was passiert mit dem vermeintlich „verschwendeten“ Bit? Damit könnten wir doch immerhin 128 weitere Symbole abbilden. Und das wird auch gemacht: Es gibt verschiedene lokale Erweiterungen des ASCII-Codes, die zusätzliche Zeichen definieren. Für den deutschen Sprachraum etwa die Umlaute ä, ö, ü und das scharfe S (ß). Für andere Sprachen gibt es ähnliche Erweiterungen. Wir nennen diese Erweiterungen auch Codepages.
Die Codepage, die wir üblicherweise verwenden, nennt sich Windows-1252 (CP-1252) und ist eine Erweiterung des ASCII-Codes, die 256 Zeichen umfasst. Die ersten 128 Zeichen sind identisch mit dem ASCII-Code, die weiteren 128 enthalten zusätzliche Zeichen, die in westeuropäischen Sprachen benötigt werden.
Abbildung 3.4: Die ursprüngliche ASCII-Codetabelle kodiert die Symbole als 7-Bit-Binärzahlen
Der ASCII-Code – das steht für American Standard Code for Information Interchange – beinhaltet ein paar nette Eigenschaften. So können wir zum Beispiel einen Großbuchstaben in einen Kleinbuchstaben umwandeln, indem wir 32 zu seinem Dezimalcode addieren. Umgekehrt funktioniert das natürlich auch.
Für unsere Texteingabe über den IR-Abstandssensor bedeutet das: Wir benötigen überhaupt keinen eigenen Code, sondern können einfach den ASCII-Code verwenden. Allerdings müssen wir unsere Nachricht auf die Länge 7 erweitern, was mehr Aufwand bei der Eingabe macht. Dafür verwenden wir einen Standard. Argument genug – passen wir den Code an.
Die Änderungen finden im Wesentlichen in der Funktion decode_letter() statt. Zudem ändern wir den Wert der Konstante MESSAGE_LENGTH:
MESSAGE_LENGTH =7# Anzahl Bits pro Buchstabe...def decode_letter(bits):# Links eine 0 hinzufügen, damit es 8 Bits sind bits ="0"+ bits# Binärstring in Dezimalzahl und dann in ASCII-Zeichen umwandeln decimal =int(bits, 2)returnchr(decimal)
Die decode_letter()-Funktion fügt nun zunächst dem übergebenen Bit-String, der aus 7 Bits bestehen sollte, eine 0 an den Anfang hinzu. Damit haben wir die 8 Bits aus der ASCII-Tabelle in Abbildung 3.4 komplettiert. Anschließend erfolgt – wie zuvor – die Konvertierung von binär nach dezimal. Die wesentliche Änderung steht in der Zeile darunter: Wir geben das Ergebnis der Funktion chr() zurück, der wir den Dezimalwert unseres kodierten Symbols übergeben. Brauchen wir also kein Dictionary mehr?
Ganz genau! Es gibt bereits eine Funktion, die die passenden Symbole für Codes liefern kann. Wenn wir in die offizielle Dokumentation der Funktion chr() schauen, dann steht dort:
Return the string representing a character with the specified Unicode code point. For example, chr(97) returns the string ‘a’, while chr(8364) returns the string ‘€’. This is the inverse of ord().
Die Funktion gibt also die Repräsentation des Codes als Zeichen zurück. Aber was steht da? Mit dem angegebenen Unicode-Codepunkt? Was ist denn jetzt schon wieder Unicode? Wir haben doch gerade über ASCII gesprochen.
3.6.1 Unicode
Unicode ist ein internationaler Standard, der jedes Zeichen aus praktisch allen Schriftsystemen der Welt eindeutig beschreibt. Während ASCII nur 128 Symbole umfasst und damit vor allem die englische Sprache abdeckt, definiert Unicode einen gemeinsamen Zeichensatz mit weit über einer Million möglichen Codepunkten. Ein Codepunkt ist dabei eine Nummer, die einem Zeichen zugeordnet ist, zum Beispiel hat der Buchstabe „A“ den Codepunkt U+0041 und das Eurozeichen „€“ den Codepunkt U+20AC.
Wichtig ist die Unterscheidung zwischen Zeichensatz und Kodierung: Unicode ist der Zeichensatz (die Menge aller Zeichen mit ihren Codepunkten), während Formate wie UTF-8, UTF-16 oder UTF-32 beschreiben, wie diese Codepunkte als Bits und Bytes gespeichert oder übertragen werden. UTF-8 ist heute die am weitesten verbreitete Kodierung im Web. Sie ist variabel lang und hat eine zentrale Eigenschaft: Die ersten 128 Codepunkte (0–127) entsprechen exakt dem ASCII-Code. Dadurch ist UTF-8 vollständig rückwärtskompatibel zu ASCII. Eine reine ASCII-Datei ist zugleich gültiges UTF-8, und Funktionen wie chr() und ord() in Python arbeiten mit Unicode-Codepunkten. Wenn ihr also chr(65) aufruft, erhaltet ihr „A“ – das passt sowohl in ASCII als auch in Unicode. Für Zeichen außerhalb des ASCII-Bereichs verwendet UTF-8 mehr als ein Byte, bleibt aber weiterhin eindeutig und effizient.
UTF-8 verwendet je nach Zeichen unterschiedlich viele Bytes – zwischen einem und vier. Häufige Zeichen wie die ASCII-Buchstaben brauchen nur 1 Byte. Ein „A“ hat den Codepunkt U+0041 und wird in UTF-8 als 0x41 gespeichert. Zeichen mit Akzenten benötigen oft 2 Bytes, zum Beispiel „ä“ (U+00E4) als 0xC3 0xA4. Das Eurozeichen „€“ (U+20AC) braucht 3 Bytes: 0xE2 0x82 0xAC. Ein Emoji wie „😊“ (U+1F60A) benötigt 4 Bytes: 0xF0 0x9F 0x98 0x8A.
Eine hilfreiche Analogie: Stellt euch UTF-8 wie einen Paketdienst mit vier Paketgrößen (S, M, L, XL) vor. Die meisten Sendungen (ASCII-Zeichen) passen in Größe S und sind damit sehr platzsparend. Für seltenere oder komplexere Zeichen wird automatisch eine größere Paketgröße gewählt. Am „Adressaufkleber“ – den ersten Bits des ersten Bytes – erkennt der Empfänger sofort, wie groß das Paket ist und wie viele Folgebytes er einlesen muss. So bleibt Text kompakt, und reine ASCII-Texte sind automatisch gültiges UTF-8.
Auf diese Weise wird sichergestellt, dass die häufigsten Zeichen möglichst wenig Speicherplatz benötigen, während dennoch alle Zeichen der Welt eindeutig kodiert werden können. Das macht UTF-8 zur bevorzugten Wahl für die Textverarbeitung in modernen Anwendungen und im Web. Ihr könnt das übrigens selbst einmal überprüfen: Erstellt zwei leere Textdateien und speichert beide als UTF-8. Fügt in die erste einen Text nur aus Buchstaben, Zahlen und Leerzeichen ein und in die zweite einen Text mit Sonderzeichen und Emojis. Dabei sollte in jeder Datei die gleiche Anzahl Zeichen stehen. Wie unterscheidet sich die Größe der Dateien im Dateiexplorer?
3.7 LED-Dimmer 4.0
In Kapitel 2 haben wir bereits drei Versionen eines LED-Dimmers gebaut. Eine letzte, vierte Variante kommt noch dazu: Lasst uns schauen, ob wir die Helligkeit mit dem Abstandssensor steuern können.
Das war wieder einmal eine rhetorische Frage, natürlich können wir das! Mit Computern lässt sich so gut wie jedes Problem lösen, es geht nur um das Wie. Vielleicht habt ihr schon eine Idee, nachdem wir den Abstandssensor in diesem Kapitel schon intensiv kennengelernt haben.
Der Dimmer aus Kapitel 2 lässt die LED in verschiedenen Stufen heller und dunkler leuchten. Über den Drehknopf haben wir zunächst 1er-Schritte umgesetzt, was bedeutete, dass wir 256 Ticks des Drehknopfs benötigten, um die LED auf volle Helligkeit zu schalten. Später haben wir dann eine Konstante STEP eingeführt, um die Schritte zu vergrößern, sodass nur noch eine Umdrehung notwendig war.
Wie lässt sich das auf den Abstandssensor übertragen? Im Gegensatz zum Drehknopf, den wir beliebig lange in eine Richtung drehen können, hat der Abstandssensor einen festen Messbereich zwischen 4 und 30 cm. Das macht unsere Aufgabe einfacher, denn eine Transformation des Messbereichs in den Helligkeitsbereich der LED ist ausreichend. Wenn der Abstandssensor nun einen Wert von 4 cm misst, soll die LED auf 0 % Helligkeit dimmen, und bei 30 cm auf 100 % Helligkeit.
Nehmen wir an, der aktuelle Messwert ist in distance gespeichert, dann könnten wir den Helligkeitswert brightness so berechnen:
brightness = (distance -40) / (300-40) *255
Vergewissern wir uns, dass die Formel richtig ist. Wenn distance den Wert 4 cm hat, dann sollte brightness 0 sein. Das passt, denn der erste Teil der Formel wird dann 0. Und 0 geteilt durch egal was ergibt 0. Wenn distance = 300, dann sollte brightness 255 sein. Das passt ebenfalls, denn der erste Teil der Formel wird dann 260 und 260 geteilt durch 260 ergibt 1. Multipliziert mit 255 ergibt 255. Sieht also gut aus.
Der folgende Code baut die Berechnungslogik in den LED-Dimmer aus Abschnitt 2.7 ein, der nur eine Farbe (Weiß) beherrscht. Wir könnten ihn aber genau wie in Abschnitt 2.9 um weitere Farben erweitern:
Je näher wir mit der Hand an den Sensor kommen, desto dunkler wird die LED – und umgekehrt.
Damit schließen wir dieses Kapitel ab. Wir haben gelernt, wie Computer Texte kodieren. Der Umweg über unser eigenes Eingabegerät für Binärcodes hat sich gelohnt: Eure Programmierskills sind gewachsen!
Im folgenden Kapitel beschäftigen wir uns mit Bildern, wie Computer sie sehen, und wie ein Bild auf den Bildschirm kommt.
Adami, Christoph. 2016. „What is Information?“Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 374 (2063): 20150230. https://doi.org/10.1098/rsta.2015.0230.
Brookshear, J. Glenn, und Dennis Brylow. 2020. Computer science: an overview. 13th edition, global edition. NY, NY: Pearson.
Gallenbacher, Jens. 2020. Abenteuer Informatik: IT zum Anfassen für alle von 9 bis 99, vom Navi bis SocialMedia. 4. Auflage, korrigierte Publikation. Berlin Heidelberg: Springer.
Petzold, Charles. 2022. Code: the hidden language of computer hardware and software. 2. Aufl. Hoboken: Microsoft Press.
Pólya, George, und John Horton Conway. 2004. How to solve it: a new aspect of mathematical method. Expanded Princeton Science Library ed. Princeton science library. Princeton [N.J.]: Princeton University Press.
Scott, John C. 2009. But how do it know?: the basic principles of computers for everyone. Oldsmar, FL: John C. Scott.