6 Regeln vs. Lernen
6.1 Zusammenfassung
Im ersten Teil des Buches haben wir wichtige Grundlagen der Programmierung gelernt. Wir haben gesehen, wie Computer Probleme lösen: Sie stellen Dinge aus der analogen Welt in einer digitalen Form dar und wenden dann Verarbeitungsschritte (Algorithmen) an, um daraus eine Lösung zu bauen. Dabei haben wir als Menschen die genauen Schritte vorgegeben und in einer Programmiersprache kodiert, in unserem Beispiel mit Python.
Im zweiten Teil des Buches, der mit diesem Kapitel beginnt, schauen wir uns eine ganz andere Herangehensweise an: maschinelles Lernen. Dabei geben wir dem Computer nicht mehr jeden einzelnen Schritt zur Lösung vor. Stattdessen soll er die Logik selbst entdecken — oder lernen. Aber wie können Computer lernen? Indem wir ihm viele bereits gelöste Beispiele als Daten zeigen und ihn so trainieren, dass er aus diesen Beispielen Regeln ableitet. Die Hoffnung ist: Mit diesen gelernten Regeln kann er auch neue Fälle lösen, die er noch nie gesehen hat.
Wenn Computer aus Beispielen lernen sollen — was machen wir Menschen dann überhaupt noch, wenn wir nicht mehr alle Regeln selbst aufschreiben? Genau hier liegt der große Unterschied.
Der Wechsel von “Menschen geben dem Computer die Regeln für die Lösung vor” zu “Menschen lassen den Computer die Regeln erlernen” ist ein Paradigmenwechsel. Zwar müssen wir Menschen weiterhin Regeln entwerfen, aber nicht mehr für die Lösung selbst. Stattdessen entwerfen wir einen Algorithmus, der es Computern ermöglicht, aus Daten zu lernen. Wir sprechen dann von Algorithmen des maschinellen Lernens.
In diesem Kapitel führen wir gemeinsam ein Experiment durch, um die regelbasierte Lösung eines konkreten Problems einer lernbasierten Lösung gegenüberzustellen. Stellt euch vor, eure Firma hat einen Chatbot auf der Webseite platziert, der Kundenanfragen entgegennimmt. Der Chatbot spricht mit den Kunden und fragt sie nach ihrem Anliegen, bevor er sie an einen menschlichen Mitarbeiter weiterleitet. Der Chatbot soll auf Basis der Kundenantworten einen Hinweis geben, ob der Kunde gute oder schlechte Laune hat. Die Kernfrage ist also: Wie kann der Chatbot die Laune eines Kunden anhand der Chatnachrichten erkennen?
6.2 Experimentaufbau
Für das Experiment benötigen wir eine LED (RGB LED Bricklet 2.0), die wir aus dem ersten Teil des Buches bereits kennen. Damit wir die LED steuern können, benötigen wir auch den passenden Mikrocontroller (Master Brick 3.2). Wir können also das komplette Hardware-Setup aus Kapitel 1 wiederverwenden.
Die vollständige Hardwareliste für dieses Kapitel sieht so aus:
- 1 x Master Brick 3.2
- 1 x RGB LED Bricklet 2.0
- 1 x Montageplatte 22x10
- 1 x Brickletkabel 15cm (7p-7p)
- 1 x Befestigungskit 12 mm
Neben der Hardware benötigt ihr auch die passende Software. Diese solltet ihr bereits installiert haben, wenn ihr den ersten Teil des Buches abgeschlossen habt. Falls nicht, schaut im Abschnitt zu den Voraussetzungen vorbei. Dort ist alles genau beschrieben. Im Folgenden gehe ich davon aus, dass auf eurem Rechner alles läuft.



Wozu die LED? Über die LED wird dem menschlichen Mitarbeiter signalisiert, ob der Chatbot glaubt, dass der Kunde gute oder schlechte Laune hat. Die LED soll grün leuchten, wenn der Kunde gute Laune hat und ein positives Anliegen äußert, zum Beispiel Lob, eine Bestellung oder konstruktive Kritik. Sie soll rot leuchten, wenn der Kunde schlechte Laune hat und ein negatives Anliegen äußert, zum Beispiel eine Beschwerde, eine Rückgabe oder eine wütende Nachricht. Sollte der Chatbot unsicher sein, weil die Nachricht unklar ist, soll die LED blau leuchten.
Neben der LED als Hardware benötigen wir für dieses Experiment auch etwas Zusätzliches auf der Softwareseite. Wir werden im zweiten Teil des Experiments auf ein Sprachmodell von OpenAI zurückgreifen, das auch hinter ChatGPT steckt, und es in unsere Lösung einbauen. Damit wir aus unserem Python-Programm auf dieses Modell zugreifen können, brauchen wir die passende Softwarebibliothek sowie einen API-Schlüssel, damit OpenAI weiß, wer wir sind und unsere Modellnutzung abrechnen kann.
Die Softwarebibliothek von OpenAI installiert ihr mit folgendem Befehl. Achtet darauf, dass ihr eure virtuelle Python-Umgebung vorher aktiviert habt, wenn ihr eine verwendet, was ich euch empfehle:
Den API-Schlüssel bekommt ihr im Rahmen einer Lehrveranstaltung direkt von mir. Solltet ihr nicht an der Hochschule Osnabrück studieren, könnt ihr euch auf der OpenAI-Website registrieren und einen eigenen API-Schlüssel generieren. Die Kosten, die euch für dieses Experiment entstehen, sind mit wenigen Cents sehr gering.
6.3 Ein Chatbot mit Python
Um unnötigen Aufwand zu vermeiden, erstellen wir im ersten Schritt einen einfachen Chat auf Basis eines Python-Programms. Der Chat soll keine richtige Chatoberfläche haben, wie ihr sie aus ChatGPT kennt, sondern einfach über die Kommandozeile laufen. Schließlich geht es in diesem Kapitel um den Unterschied zwischen Regeln und Lernen und nicht um die Entwicklung von Benutzeroberflächen.
Das Python-Programm übernimmt dabei die Rolle des Chatbots. Es nimmt die Kundenanfrage entgegen, erkennt die Laune des Kunden und steuert die LED entsprechend. Wie wir eine Texteingabe vom Nutzer über die Kommandozeile entgegennehmen, haben wir bereits in Kapitel 4 kurz gesehen. Dort ging es allerdings nur um das Drücken der ENTER-Taste, damit das Programm fortfährt. Mit derselben Funktion können wir aber auch beliebigen Text einlesen:
Sobald der Nutzer einen Text eingibt und ENTER drückt, speichert Python die Eingabe in der Variable message. Wir können sie dann weiterverarbeiten.
Damit unser Chatbot mehrere Nachrichten nacheinander entgegennehmen kann, brauchen wir eine Schleife. Sie soll so lange laufen, bis der Nutzer bye eingibt:
Jetzt fügen wir die Verbindung zur LED hinzu. Legt eine neue Datei namens mood_rb.py an — das rb steht für rule-based, also regelbasiert. Das ist die Datei, die wir im weiteren Verlauf schrittweise ausbauen:
# mood_rb.py
# Stimmungserkennung mit einem regelbasierten Ansatz
from tinkerforge.ip_connection import IPConnection
from tinkerforge.bricklet_rgb_led_v2 import BrickletRGBLEDV2
# Verbindung zum Master Brick herstellen
ipcon = IPConnection()
ipcon.connect("localhost", 4223)
# LED-Bricklet initialisieren (UID bitte anpassen!)
led = BrickletRGBLEDV2("xxx", ipcon)
# LED zu Beginn ausschalten
led.set_rgb_value(0, 0, 0)
# Schleife: Nachrichten empfangen, bis der Nutzer "bye" eingibt
while True:
message = input("Deine Nachricht: ")
if message == "bye":
print("Tschüss!")
break
print("Empfangen:", message)
# Verbindung am Ende trennen
ipcon.disconnect()Testet das Programm kurz, bevor ihr weitermacht. Stellt sicher, dass die LED beim Start ausgeschaltet ist und dass ihr Nachrichten eintippen könnt. Ab jetzt habt ihr die Grundstruktur — sie bleibt, und wir fügen Schritt für Schritt die eigentliche Erkennungslogik hinzu.
6.4 Von Bauchgefühl zu Regeln
Bevor wir die erste Zeile Erkennungslogik schreiben, machen wir einen kurzen Schritt zurück. Denn um Regeln programmieren zu können, müssen wir erst wissen: Was für Regeln sind das überhaupt?
Stellt euch vor, ein menschlicher Mitarbeiter liest die Nachrichten der Kunden und entscheidet intuitiv, ob jemand gute oder schlechte Laune hat — ohne darüber groß nachzudenken. Die meisten von uns können das, weil wir durch Erfahrung und viele Gespräche gelernt haben, wie wir die Stimmung eines Menschen anhand seiner Worte einschätzen können. Dieses Wissen ist implizit: Es ist einfach da, und wir nutzen es, ohne es je explizit formuliert zu haben.
Wenn ihr die folgenden zehn Sätze lest, habt ihr wahrscheinlich sofort ein Gefühl dafür, wie die jeweilige Person gestimmt ist:
- Not bad at all, actually.
- Well, that could have gone worse.
- I guess this is fine.
- Oh great, another problem.
- I’m not unhappy with the result.
- Fantastic… now it’s broken again.
- I was worried, but now it seems okay.
- That’s just perfect.
- I can live with that.
- It’s working, though I don’t feel great about it.
Probiert es aus: Lest jeden Satz und entscheidet euch für eines der Labels good, bad oder neutral. Macht das zuerst für euch alleine, dann vergleicht ihr eure Ergebnisse mit denen einer aneren Person (einer Kommilitonin oder einem Kommilitonen, Bruder/Schwester, Eltern). Für jeden Satz, bei dem ihr unterschiedliche Entscheidungen getroffen habt, schreibt auf, welche Regel ihr angewendet habt — oder zu haben glaubt. Diese Regeln sind der Rohstoff für den nächsten Schritt. Genau sie wollen wir jetzt in Python übersetzen.
6.5 Laune über Regeln erkennen
Wie lässt sich das, was wir intuitiv können, in ein Programm übersetzen? Der naheliegendste Ansatz ist ein regelbasiertes System: Wir überlegen uns, welche Wörter typischerweise auf eine gute oder schlechte Stimmung hinweisen, und prüfen dann, ob eines dieser Wörter in der eingehenden Nachricht vorkommt.
Beginnen wir mit zwei Listen, eine für positive Wörter, eine für negative:
# Wörter, die auf gute Stimmung hinweisen
good_words = ["great", "fantastic", "happy", "good", "wonderful",
"excellent", "love", "perfect", "okay", "fine", "glad"]
# Wörter, die auf schlechte Stimmung hinweisen
bad_words = ["bad", "terrible", "awful", "broken", "problem",
"hate", "wrong", "angry", "annoyed", "frustrated"]Diese Listen sind unser Regelwerk. Sie legen fest, welche Bedeutung wir einem Wort zuordnen. Natürlich sind solche Listen nie vollständig. Aber sie reichen als Ausgangspunkt.
Als nächstes schreiben wir eine Funktion, die eine Nachricht entgegennimmt und eines der Labels zurückgibt. Wir wandeln die Nachricht zuerst in Kleinbuchstaben um, damit Groß- und Kleinschreibung keine Rolle spielt:
def detect_mood(message):
# In Kleinbuchstaben umwandeln, damit "Bad" und "bad" gleich behandelt werden
message_lower = message.lower()
# Prüfen, ob ein negatives Wort vorkommt
for word in bad_words:
if word in message_lower:
return "bad"
# Prüfen, ob ein positives Wort vorkommt
for word in good_words:
if word in message_lower:
return "good"
# Kein bekanntes Wort gefunden
return "neutral"Jetzt können wir die Funktion in die Chatbot-Schleife einbauen und die LED entsprechend steuern. Fügt diese Zeilen nach print("Empfangen:", message) ein:
Testet euren Detektor jetzt auf den zehn Sätzen von oben. Wie viele erkennt er richtig? Wo schlägt er fehl?
Ihr werdet schnell merken, dass einige Sätze das System vor Probleme stellen. Satz d — „Oh great, another problem.” — enthält das Wort „great”, das eigentlich für gute Stimmung steht, aber der Satz ist sarkastisch gemeint. Satz e — „I’m not unhappy with the result.” — enthält das Wort „unhappy”, aber das „not” davor dreht die Bedeutung ins Positive. Einfache Wortlisten können solche sprachlichen Feinheiten nicht abbilden.
6.5.1 Grenzen einfacher Regeln
Geht weiter auf Fehlersuche und schaut euch die Funktion genau an. Was passiert bei Satz j — „It’s working, though I don’t feel great about it.”? Die Nachricht enthält das positive Wort „great” und kein negatives Wort aus unserer Liste — also gibt die Funktion "good" zurück. Aber die Nachricht drückt eher Ambivalenz aus, kein positives Gefühl.
Das liegt an einem grundlegenden Problem: Die Funktion gibt beim ersten Treffer sofort ein Ergebnis zurück. Welches Wort zuerst gefunden wird, hängt von der Reihenfolge in den Listen und der Position im Satz ab — nicht davon, was die Nachricht als Ganzes aussagt.
Ein robusterer Ansatz wäre, alle Signale in der Nachricht zu zählen: Wie viele positive Wörter kommen vor? Wie viele negative? Das Label mit dem höheren Zählwert gewinnt. Damit kann eine einzige Erwähnung eines negativen Wortes nicht mehr alle positiven Signale übertrumpfen:
def detect_mood_counting(message):
message_lower = message.lower()
# Positive und negative Treffer zählen
good_count = 0
bad_count = 0
for word in good_words:
if word in message_lower:
good_count += 1
for word in bad_words:
if word in message_lower:
bad_count += 1
# Das Label mit dem höheren Zählwert gewinnt
if good_count > bad_count:
return "good"
elif bad_count > good_count:
return "bad"
else:
return "neutral"Auch dieser Ansatz hat Grenzen. Bei einem Gleichstand zwischen positiven und negativen Treffern wird die Nachricht als neutral eingestuft — obwohl sie vielleicht einfach gemischte Gefühle ausdrückt. Negationen wie „not good” werden nach wie vor nicht erkannt. Und was ist mit Intensitäten: Ist „absolutely fantastic” stärker als „okay”?
Das ist eine zentrale Erkenntnis über regelbasierte Systeme: Je näher sie der Wirklichkeit kommen sollen, desto komplexer werden die Regeln. Für jede Ausnahme brauchen wir eine neue Regel — und mit jeder neuen Regel steigt die Wahrscheinlichkeit, dass irgendwo eine andere Regel bricht. Irgendwann wird das System unbeherrschbar.
6.5.2 Ein viertes Label
Drei Labels reichen oft nicht. Manche Nachrichten lassen sich als positiv oder negativ einordnen, aber das trifft ihre eigentliche Bedeutung nicht. Satz d und Satz f sind gute Beispiele dafür: Sie klingen positiv, meinen aber das Gegenteil. Das ist Sarkasmus — und Sarkasmus ist für regelbasierte Systeme besonders schwer zu erkennen, weil die Wörter und die gemeinte Bedeutung auseinanderfallen.
Wählt gemeinsam ein viertes Label für euer System. Ein guter Kandidat ist sarcastic. Ergänzt eure Wortlisten um typische sarkastische Formulierungen. Sarkasmus lässt sich oft an festen Phrasen erkennen, daher verwenden wir diesmal keine einzelnen Wörter, sondern ganze Ausdrücke:
Passt jetzt die Funktion detect_mood an. Sarkasmus soll zuerst geprüft werden, weil er Vorrang vor einfachen Worttreffern hat — ein sarkastisches „oh great” soll nicht als gute Stimmung erkannt werden:
def detect_mood(message):
message_lower = message.lower()
# Erst auf Sarkasmus prüfen — hat Vorrang vor den anderen Labels
for phrase in sarcastic_phrases:
if phrase in message_lower:
return "sarcastic"
# Dann auf schlechte Stimmung prüfen
for word in bad_words:
if word in message_lower:
return "bad"
# Dann auf gute Stimmung prüfen
for word in good_words:
if word in message_lower:
return "good"
# Kein bekanntes Muster gefunden
return "neutral"Und die LED-Steuerung bekommt eine neue Farbe für das vierte Label:
Überlegt dabei: Was verrät die Wahl dieses vierten Labels über eure Annahmen zu menschlicher Kommunikation? Und welche Stimmungen gibt es, die ihr mit keinem eurer vier Labels erfassen könnt?
6.5.3 Fertige Datei mood_rb.py
Hier ist die vollständige mood_rb.py mit allem, was wir bisher entwickelt haben:
# mood_rb.py
# Stimmungserkennung mit einem regelbasierten Ansatz
from tinkerforge.ip_connection import IPConnection
from tinkerforge.bricklet_rgb_led_v2 import BrickletRGBLEDV2
# Verbindung zum Master Brick herstellen
ipcon = IPConnection()
ipcon.connect("localhost", 4223)
# LED-Bricklet initialisieren (UID bitte anpassen!)
led = BrickletRGBLEDV2("xxx", ipcon)
led.set_rgb_value(0, 0, 0)
# Wörter und Phrasen für die Stimmungserkennung
good_words = ["great", "fantastic", "happy", "good", "wonderful",
"excellent", "love", "perfect", "okay", "fine", "glad"]
bad_words = ["bad", "terrible", "awful", "broken", "problem",
"hate", "wrong", "angry", "annoyed", "frustrated"]
sarcastic_phrases = ["oh great", "just perfect", "fantastic... now",
"yeah right", "how wonderful", "oh sure"]
def detect_mood(message):
message_lower = message.lower()
for phrase in sarcastic_phrases:
if phrase in message_lower:
return "sarcastic"
for word in bad_words:
if word in message_lower:
return "bad"
for word in good_words:
if word in message_lower:
return "good"
return "neutral"
# Chatbot-Schleife
while True:
message = input("Deine Nachricht: ")
if message == "bye":
print("Tschüss!")
break
mood = detect_mood(message)
print("Erkannte Stimmung:", mood)
if mood == "good":
led.set_rgb_value(0, 255, 0)
elif mood == "bad":
led.set_rgb_value(255, 0, 0)
elif mood == "sarcastic":
led.set_rgb_value(255, 255, 0)
else:
led.set_rgb_value(0, 0, 255)
ipcon.disconnect()6.6 Lernbasierte Launeerkennung
Das regelbasierte System funktioniert für viele Fälle gut — aber es stößt schnell an seine Grenzen. Negationen, Sarkasmus, mehrdeutige Formulierungen: All das überfordert ein einfaches Wörterbuch. Und jede neue Ausnahme bedeutet: Wir müssen manuell eine neue Regel hinzufügen. Das ist aufwendig und fehleranfällig.
Was wäre, wenn wir das Problem einem System überlassen könnten, das bereits gelernt hat, wie Sprache funktioniert? Genau das sind moderne Sprachmodelle wie das Modell hinter ChatGPT. Diese Modelle wurden auf riesigen Mengen menschlicher Texte trainiert und haben dabei implizit gelernt, wie Stimmung, Sarkasmus und sprachliche Nuancen zusammenhängen. Sie tragen das Wissen, das wir mühsam in Regeln zu fassen versuchen, bereits in sich.
6.6.1 Erste Experimente mit ChatGPT
Bevor wir eine Zeile Python schreiben, macht einen kurzen Abstecher zu ChatGPT. Öffnet chatgpt.com im Browser und testet, ob ein Sprachmodell die Aufgabe überhaupt lösen kann — und wenn ja, wie.
Der entscheidende Schritt ist, dem Modell klar zu sagen, was es tun soll. Das geschieht über einen Prompt — eine Texteingabe, die die Aufgabe beschreibt. Ein Prompt ist nicht einfach eine Frage: Er kann Anweisungen, Beispiele, Rahmenbedingungen und die eigentliche Eingabe enthalten. Beginnt mit etwas wie:
Classify the mood of a message as one of: good, bad, neutral, sarcastic. Message: I love this product.
Ihr seht das Muster: Erst die Aufgabenbeschreibung mit den erlaubten Labels, dann — am Ende — die eigentliche Nachricht. Das ist kein Zufall. Der Text am Ende ist das, was sich später im Code durch eine Variable ersetzen lässt. Heute tippt ihr ihn noch von Hand ein; in ein paar Minuten wird dort {message} stehen.
Warum auf Englisch? Formuliert euren Prompt auf Englisch, auch wenn die Aufgabe an sich Englisch und Deutsch gemischt ist. Sprachmodelle wie GPT wurden überwiegend auf englischsprachigen Texten trainiert. Mehrere Studien zeigen, dass die Genauigkeit bei englischen Prompts deutlich höher ist als bei Prompts in anderen Sprachen (Better to Ask in English: Evaluation of Large Language Models on English, Low-resource and Cross-Lingual Settings 2024; Multilingual Prompts in LLM-Based Recommenders: Performance Across Languages 2024). Das gilt insbesondere für Klassifikationsaufgaben, bei denen das Modell ein präzises Label zurückgeben soll.
Modell und Anwendung sind getrennt. Etwas, das beim ersten Umgang mit ChatGPT leicht übersehen wird: ChatGPT ist nicht das Modell — ChatGPT ist eine Anwendung, die auf dem Modell aufbaut. Das Modell (zum Beispiel GPT-4o) ist das eigentliche lernende System, das Texte versteht und erzeugt. ChatGPT ist eine Oberfläche, die dieses Modell zugänglich macht — mit Chatfenster, Verlauf, Einstellungen und allem, was dazugehört. Andere Anwendungen — wie unser Python-Programm, aber auch externe Dienste von Drittanbietern — nutzen dasselbe Modell über eine Programmierschnittstelle, die sogenannte API.
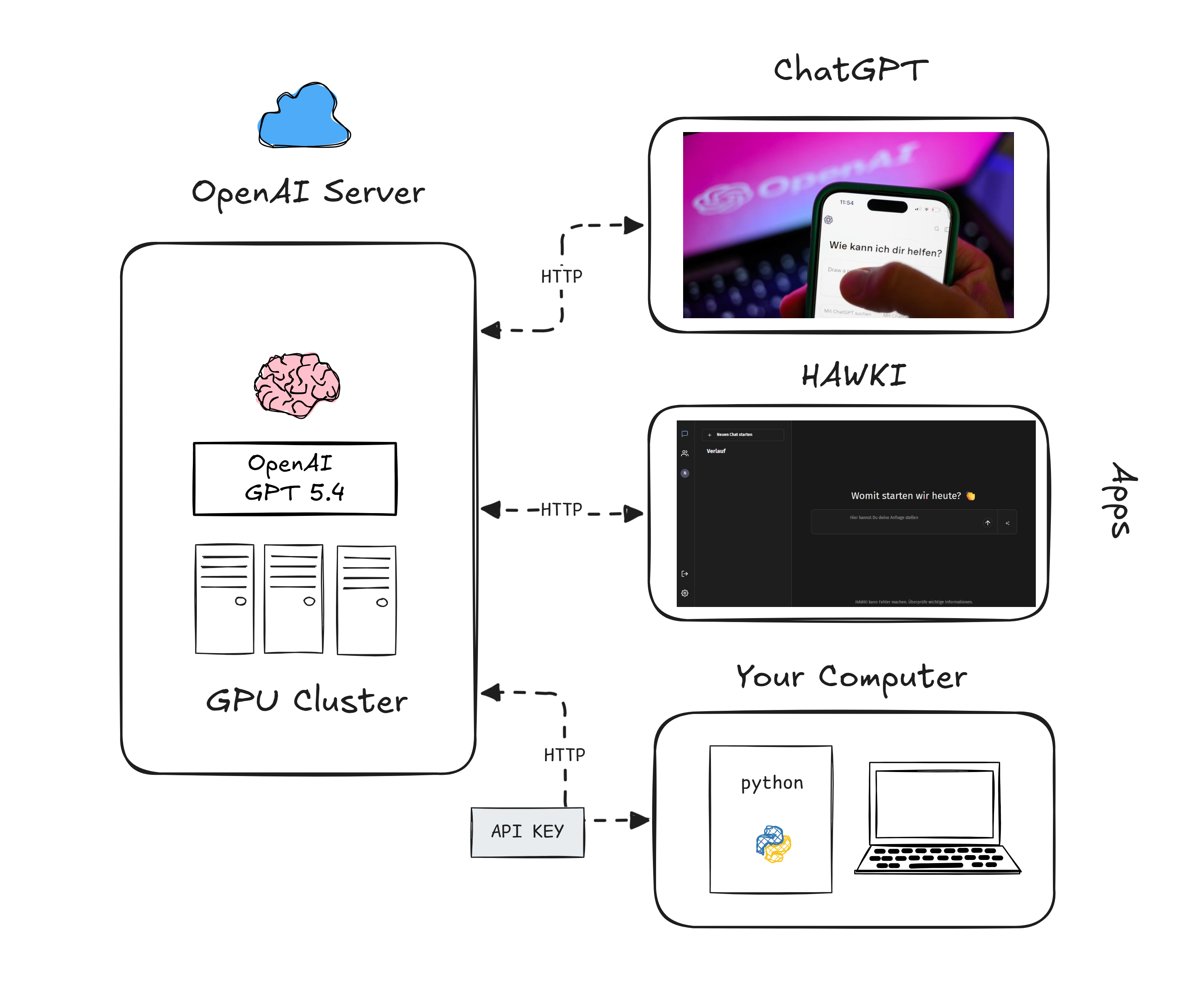
Prompt-Engineering. Testet jetzt die zehn Sätze von oben — einen nach dem anderen. Beobachtet dabei: Antwortet das Modell immer mit genau einem der vier Labels? Oder schreibt es manchmal einen ganzen Satz? Weicht die Groß- und Kleinschreibung ab? Kommen manchmal Erklärungen dazu?
Passt euren Prompt an, bis die Antworten kurz, einheitlich und direkt verwendbar sind. Das Anpassen eines Prompts, um das gewünschte Verhalten zu erzielen, nennt man Prompt-Engineering. Es ist keine exakte Wissenschaft — manchmal helfen kleine Formulierungsänderungen erheblich. Zum Beispiel:
- „Reply with only the label, nothing else.” reduziert Erklärungen.
- „Use lowercase.” sorgt für einheitliche Groß- und Kleinschreibung.
- Eine explizite Auflistung der erlaubten Labels verhindert, dass das Modell eigene Kategorien erfindet.
Notiert den Prompt, den ihr zuletzt verwendet habt. Ihr werdet ihn gleich im Code brauchen.
6.6.2 Verbindung zur OpenAI-API
Jetzt bringen wir das Sprachmodell in unser Python-Programm. Legt eine neue Datei namens mood_ml.py an — als Kopie von mood_rb.py. Entfernt die Wortlisten und die detect_mood-Funktion. Was bleibt, ist die Grundstruktur: Verbindung zur LED, Eingabeschleife und LED-Steuerung.
Als erstes importieren wir die OpenAI-Bibliothek und richten die Verbindung ein. Den API-Schlüssel tragt ihr direkt als Variable ein:
6.6.3 Die erste Anfrage
Jetzt schreiben wir eine Funktion, die eine Nachricht an das Sprachmodell schickt und das Ergebnis zurückgibt. Das Herzstück ist ein Prompt — der Text, mit dem wir dem Modell mitteilen, was es tun soll:
def detect_mood_llm(message):
# Prompt formulieren: Aufgabe klar beschreiben und erlaubte Labels benennen
prompt = f"""Classify the mood of the following message as exactly one of these labels:
good, bad, neutral, sarcastic.
Reply with only the label, nothing else.
Message: {message}"""
# Anfrage an das Sprachmodell senden
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": prompt}
]
)
# Antwort auslesen und bereinigen
label = response.choices[0].message.content.strip().lower()
return labelProbiert die Funktion zunächst mit ein paar Sätzen aus und gebt die rohe Antwort direkt auf der Kommandozeile aus:
Ihr werdet feststellen: Das Modell antwortet manchmal mit mehr als nur dem Label — mit Erklärungen, Satzzeichen oder unterschiedlicher Groß- und Kleinschreibung. Der Prompt muss daher sehr präzise formuliert sein, damit die Ausgabe direkt in eurem Programm verwendbar ist. Experimentiert mit verschiedenen Formulierungen und beobachtet, wie sich die Antworten verändern.
6.6.4 Strukturierte Ausgaben
Das Anpassen des Prompts kann die Ausgabe berechenbarer machen. Es gibt aber eine zuverlässigere Lösung: Structured Outputs. OpenAI ermöglicht es, das genaue Format der Modellantwort festzulegen — die Antwort entspricht dann immer exakt dieser Vorgabe.
Dafür definieren wir eine Datenstruktur mit einem Label und einer kurzen Begründung. Wir verwenden dazu eine sogenannte Pydantic-Klasse. Pydantic ist eine Python-Bibliothek zur Datenvalidierung:
Eine Pydantic-Klasse ist im Grunde eine Beschreibung, wie eine Datenstruktur aussehen soll. Wir legen fest, welche Felder sie hat und welche Werte erlaubt sind:
Literal["good", "bad", "neutral", "sarcastic"] bedeutet: Der Wert des Feldes label darf ausschließlich einer dieser vier Strings sein. Das Modell ist dann gezwungen, sich an diese Vorgabe zu halten — kein Raten, kein Parsen, keine bösen Überraschungen.
Jetzt aktualisieren wir die Funktion, um strukturierte Ausgaben zu nutzen:
def detect_mood_llm(message):
response = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": f"Classify the mood of this message: {message}"}
],
response_format=MoodResponse
)
# Die Antwort wird automatisch in ein MoodResponse-Objekt umgewandelt
result = response.choices[0].message.parsed
return result.label, result.reasonDie Antwort ist jetzt immer ein Objekt mit den Feldern label und reason. Ruft die Funktion auf und gebt beide Felder aus:
Das reason-Feld zeigt, welche Überlegung das Modell angestellt hat — das ist nützlich, um die Entscheidung nachzuvollziehen. Aber Vorsicht: Auch wenn die Begründung überzeugend klingt, kann das Ergebnis trotzdem falsch sein. Mehr dazu im Abschnitt zur Reflexion.
6.6.5 Fertige Datei mood_ml.py
So sieht mood_ml.py am Ende aus:
# mood_ml.py
# Stimmungserkennung mit einem lernbasierten Ansatz (Sprachmodell)
from openai import OpenAI
from pydantic import BaseModel
from typing import Literal
from tinkerforge.ip_connection import IPConnection
from tinkerforge.bricklet_rgb_led_v2 import BrickletRGBLEDV2
# API-Schlüssel hier eintragen
API_KEY = "euer-schluessel-hier"
# Verbindung zum OpenAI-Modell
client = OpenAI(api_key=API_KEY)
# Antwortstruktur definieren
class MoodResponse(BaseModel):
label: Literal["good", "bad", "neutral", "sarcastic"]
reason: str
def detect_mood_llm(message):
response = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": f"Classify the mood of this message: {message}"}
],
response_format=MoodResponse
)
result = response.choices[0].message.parsed
return result.label, result.reason
# Verbindung zur LED
ipcon = IPConnection()
ipcon.connect("localhost", 4223)
led = BrickletRGBLEDV2("xxx", ipcon)
led.set_rgb_value(0, 0, 0)
# Chatbot-Schleife
while True:
message = input("Deine Nachricht: ")
if message == "bye":
print("Tschüss!")
break
mood, reason = detect_mood_llm(message)
print("Stimmung: ", mood)
print("Begründung: ", reason)
if mood == "good":
led.set_rgb_value(0, 255, 0)
elif mood == "bad":
led.set_rgb_value(255, 0, 0)
elif mood == "sarcastic":
led.set_rgb_value(255, 255, 0)
else:
led.set_rgb_value(0, 0, 255)
ipcon.disconnect()6.7 Ergebnisse vergleichen
Bisher haben wir beide Systeme nur von Hand getestet — indem wir Sätze eingetippt und die LED-Farbe beobachtet haben. Das ist unzuverlässig: Wir testen nur das, was uns spontan einfällt, und vergessen leicht, wo das System vorhin noch versagt hat. Um die beiden Ansätze wirklich miteinander vergleichen zu können, brauchen wir einen systematischen Test.
6.7.1 Testdaten anlegen
Legt eine CSV-Datei namens test_data.csv an. CSV steht für Comma-Separated Values — ein einfaches Dateiformat, das eine Tabelle als Text speichert, wobei die Werte durch Kommas getrennt sind.
Die Datei soll mindestens 20 Sätze enthalten: die zehn Sätze von oben sowie zehn neue, die verschiedene Schwierigkeiten abdecken — Verneinungen, Sarkasmus, gemischte Gefühle und eindeutige Fälle. Zu jedem Satz gehört das korrekte Label als Grundwahrheit (englisch: ground truth), also eure eigene, möglichst einvernehmliche Einschätzung:
sentence,label
Not bad at all actually,good
Well that could have gone worse,neutral
I guess this is fine,neutral
Oh great another problem,sarcastic
I'm not unhappy with the result,good
Fantastic now it's broken again,sarcastic
I was worried but now it seems okay,good
That's just perfect,sarcastic
I can live with that,neutral
It's working though I don't feel great about it,neutral
I love this product,good
This is terrible,bad
Everything works perfectly,good
I am so frustrated,bad
Not the best experience,bad
Could be worse,neutral
Absolutely wonderful service,good
I hate waiting,bad
This is exactly what I needed,good
What a disaster,bad6.7.2 Automatisch testen
Jetzt schreiben wir ein Skript, das beide Systeme automatisch auf allen Sätzen testet und die Ergebnisse vergleicht. Legt eine neue Datei namens compare.py an:
# compare.py
# Vergleich von regelbasiertem und lernbasiertem Stimmungsdetektor
import csv
from mood_rb import detect_mood as detect_mood_rules
from mood_ml import detect_mood_llm
# Testdaten laden
sentences = []
with open("test_data.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
sentences.append(row)
# Ergebnisse für beide Systeme sammeln
correct_rules = 0
correct_llm = 0
print(f"{'Satz':<45} {'Erwartet':<12} {'Regeln':<12} {'LLM'}")
print("-" * 80)
for entry in sentences:
sentence = entry["sentence"]
true_label = entry["label"]
pred_rules = detect_mood_rules(sentence)
pred_llm, _ = detect_mood_llm(sentence) # Begründung wird hier nicht benötigt
if pred_rules == true_label:
correct_rules += 1
if pred_llm == true_label:
correct_llm += 1
# Satz auf 42 Zeichen kürzen, damit die Ausgabe übersichtlich bleibt
short = sentence[:42] + "..." if len(sentence) > 42 else sentence
print(f"{short:<45} {true_label:<12} {pred_rules:<12} {pred_llm}")
total = len(sentences)
print("-" * 80)
print(f"Genauigkeit Regeln: {correct_rules}/{total} = {correct_rules/total:.0%}")
print(f"Genauigkeit LLM: {correct_llm}/{total} = {correct_llm/total:.0%}")6.7.3 Verwirrungsmatrix
Genauigkeit allein sagt noch nicht alles. Interessant ist auch: Bei welchen Labels macht jedes System die meisten Fehler? Und macht es dieselben Fehler wie das andere?
Eine Verwirrungsmatrix (englisch: confusion matrix) zeigt genau das. Jede Zeile steht für das tatsächliche Label, jede Spalte für das vorhergesagte. Ein Wert auf der Diagonale bedeutet: Das System lag richtig. Ein Wert abseits der Diagonale zeigt, welches Label mit welchem anderen verwechselt wurde.
Für die Visualisierung benötigen wir die Bibliothek matplotlib. Installiert sie mit:
Ergänzt dann compare.py um folgende Funktion:
import matplotlib.pyplot as plt
def plot_confusion_matrix(true_labels, predictions, title):
labels = ["good", "bad", "neutral", "sarcastic"]
# Matrix mit Nullen initialisieren
matrix = [[0 for _ in labels] for _ in labels]
# Für jedes Beispiel: tatsächliches und vorhergesagtes Label eintragen
for true, pred in zip(true_labels, predictions):
if true in labels and pred in labels:
row = labels.index(true)
col = labels.index(pred)
matrix[row][col] += 1
# Matrix als Bild darstellen
fig, ax = plt.subplots()
ax.imshow(matrix, cmap="Blues")
ax.set_xticks(range(len(labels)))
ax.set_yticks(range(len(labels)))
ax.set_xticklabels(labels, rotation=45)
ax.set_yticklabels(labels)
ax.set_xlabel("Vorhergesagt")
ax.set_ylabel("Tatsächlich")
ax.set_title(title)
# Zahlenwerte in die Zellen schreiben
for i in range(len(labels)):
for j in range(len(labels)):
ax.text(j, i, str(matrix[i][j]), ha="center", va="center")
plt.tight_layout()
plt.savefig(title.replace(" ", "_") + ".png")
plt.show()Ruft die Funktion am Ende von compare.py für beide Systeme auf:
# Listen mit wahren Labels und Vorhersagen aufbauen
true_labels = [entry["label"] for entry in sentences]
pred_rules_all = [detect_mood_rules(entry["sentence"]) for entry in sentences]
pred_llm_all = [detect_mood_llm(entry["sentence"])[0] for entry in sentences]
plot_confusion_matrix(true_labels, pred_rules_all, "Regelbasiertes System")
plot_confusion_matrix(true_labels, pred_llm_all, "Lernbasiertes System")Schaut euch die Matrizen genau an: Wo macht jedes System die meisten Fehler? Verwechseln beide Systeme dieselben Labels — oder scheitern sie an unterschiedlichen Stellen?
Schaut euch außerdem die reason-Felder des Sprachmodells für falsche Vorhersagen an. Klingen die Begründungen trotzdem überzeugend? Was sagt euch das darüber, wie viel ihr einer Erklärung vertrauen solltet?
6.8 Reflexion
Nehmt euch Zeit, um über das Experiment nachzudenken. Schreibt eure Gedanken auf und diskutiert sie mit euren Kommilitoninnen und Kommilitonen:
In der analogen Aufgabe habt ihr manche Sätze unterschiedlich eingestuft. Wenn diese Meinungsverschiedenheiten als Trainingsdaten für ein Modell verwendet worden wären — was hätte das Modell dann gelernt?
Wo hat das regelbasierte System gut funktioniert, und wo hat es versagt?
Das Sprachmodell hat für jede Entscheidung eine Begründung geliefert — auch für die falschen. Macht eine überzeugende Begründung das Ergebnis vertrauenswürdiger? Sollte sie das?
Welches System war einfacher zu bauen? Welches ist einfacher zu debuggen? Sind das dieselben Fragen?
Welchem System würdet ihr in einer echten Anwendung mehr vertrauen — und für welche Art von Anwendung?
Das Sprachmodell, das ihr verwendet habt, wurde auf Milliarden von menschlich geschriebenen Texten trainiert, von denen viele von Menschen gelabelt oder kuratiert wurden. In welchem Sinne ist es ein lernbasiertes System — nur auf einer anderen Ebene als das, was ihr selbst gebaut habt?
Ihr habt selbst ein viertes Label entworfen. Was verrät die Wahl dieses Labels über die Annahmen, die ihr über menschliche Emotionen trefft?
Dieses Experiment gibt es hier auch als kompakte PDF-Version.